最近一年多都在负责组件化和工程建设的相关事情,换了工作之后可能有段时间都不会接触这块的东西,所以这里记录下主要做了哪些事情。
从 pod install 开始
iOS 的包管理工具主要是 CocoaPods , Swift Package Manager (aka SPM) 和 Carthage 。其中 CocoaPods 是历史最悠久的,第一次提交可以追溯到十年前 :Ten years ago today @alloy started writing @CocoaPods 。虽然说其对工程的入侵一直被人诟病,但是毫无疑问, CocoaPods 依旧是 iOS 上最受欢迎的包管理工具,根据 JetBrains 2021 的调查报告 :Swift 和 Objective-C - 2021 开发人员生态系统信息图 。大概有 70% 的开发者在使用 CocoaPods :
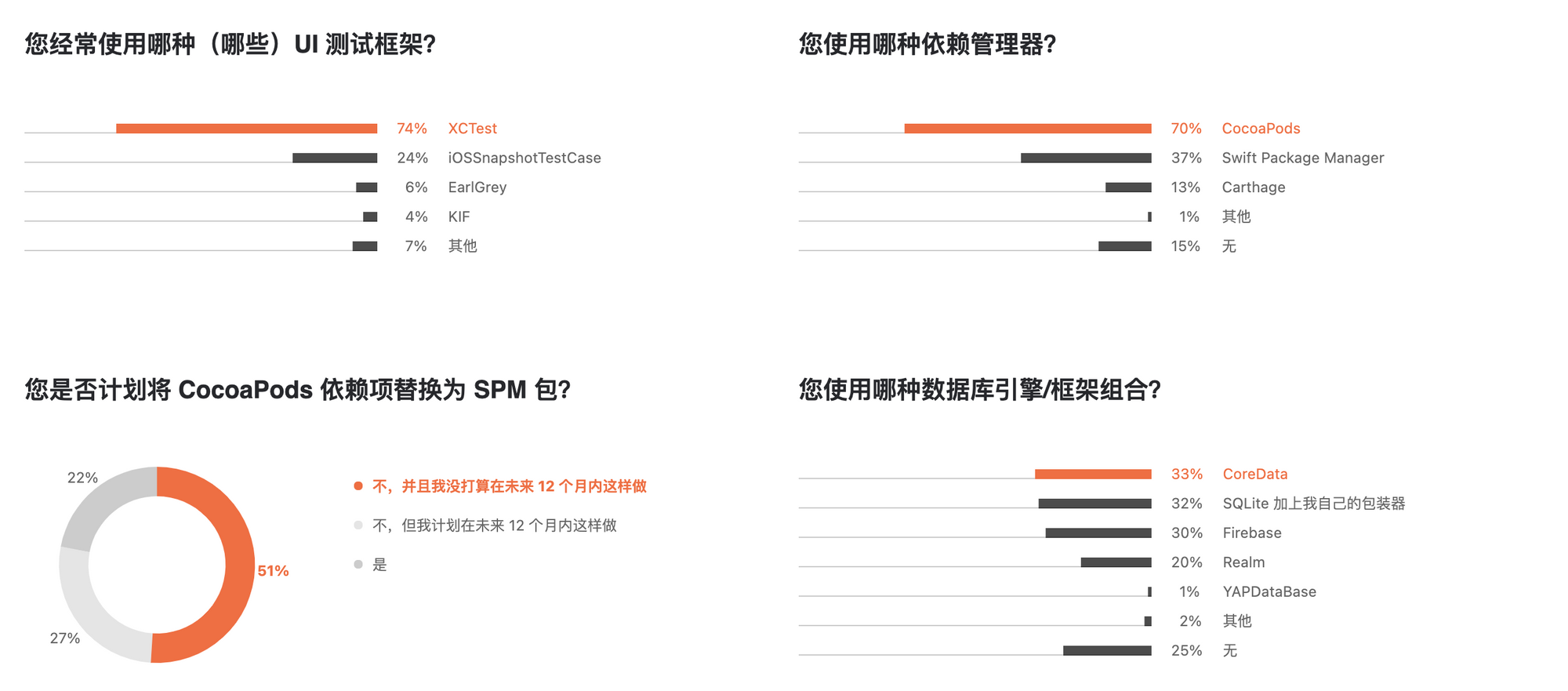
如果单看国内的数据, CocoaPods 的比例会更高。虽然下面有 51% 的开发者计划迁移到 SPM ,但是对于国内大厂来说,短期内应该不会这样操作。
所以对于国内的开发者来说,在开发过程中可能会频繁输入这条命令: pod install ,下载 Pod 库。当执行 pod install 时如果报错说找不到某个库对应的版本时,我们就会输入 pod install --repo-update ,更新本地的 Spec 源。在构建机器上执行这条命令时,为了避免 install 失败,通常来说都会默认添加 --repo-update 的参数,来更新 Spec 源。不管是拉取 CocoaPods 官方的 Spec 源还是公司内部的 Spec 源,都需要一定的耗时,但是当前这次 pod install 不一定需要更新 Spec 源,有可能在前面的构建已经有更新过,拉取到库的对应版本,这次构建时更新 Spec 源的耗时是不必要的。
为了解决这个问题, WordPress 家出了一个插件:cocoapods-repo-update 。通过 cocoapods-repo-update 插件,可以在执行 pod install 时动态判断是否需要添加 --repo-update 参数。其原理比较简单,就是通过 CocoaPods 的插件机制,对 pre_install 进行监听,在里面直接执行 CocoaPods 的依赖分析,如果没报错就不调用 update_repositories 方法。相关实现:cocoapods-repo-update/hooks.rb 。
插件目前有个 bug ,没有处理对新增库这种情况进行处理,导致其直接报错,而不是执行 update_repositories ,提了个 PR 修复:cocoapods-repo-update/pull/1 ,目前还没有合并。
当然了, CocoaPods 的依赖分析也是需要时间的,在我们公司的主工程上,每次依赖分析的耗时大概是 16s ,但是更新 Spec 源耗时是按分钟计的,网络不好时耗时更久。所以这个交易是比较划算的。
更多优化可以看这个:抖音研发效能建设 - CocoaPods 优化实践
如果没有专门的团队来做这个事情,实施起来会比较困难,可以看下有没有类似的开源方案,或者挑一些成本比较低的优化点来做。比如说将 GitHub/GitLab 的地址转为 HTTP 地址来进行下载,加快下载速度,有类似的开源方案:cocoapods-git-tarball 。如果要开启 generate_multiple_pod_projects 或者 Clang Module ,需要对 import 进行调整,可以使用 ImportSanitizer 这个工具来进行批量修改。
生成二进制产物
App 业务和体积大到一定程度之后,都会通过组件化来分隔业务线和基础框架的代码,避免它们耦合在一起或者循环依赖。而当我们把业务和基础框架拆成单独组件之后,通常来说下一步都会将它们转为二进制,减少构建耗时,否则主工程的单次构建动辄半个小时以上,尤其是发版日,需要快速修复和验证 bug ,构建耗时对效率的影响是比较大的。
组件二进制产物的生产有以下两种方式。
组件工程单独编译生成产物
开源方案:
对应文章:
优点:
- 涉及多个组件改动时可以在多台构建机器上并发进行;
- 如果有循环依赖或者错误依赖可以在单独编译时就收到相应的报错;
- 可以在多台机器间复用编译产物,一次编译,到处可用;
- 编译底层库不一定需要重新编译上层库。
缺点:
- 要有构建部门支持,根据自己的工程需要开发一套对应的组件构建和发版系统;
- 每个组件单独构建时需要单独初始化工程,比如说
pod install,有一定的耗时; - 编译环境与主工程不一致,有可能会导致一些奇奇怪怪的问题;
- 无法直接查看源码或者 debug ,需要插件支持。
通过主工程编译生成产物
开源方案:
对应的文章:
优点:
- 方便操作,接入成本比较低;
- 在构建系统上只需要初始化主工程;
- 编译环境与主工程一致,避免一些奇奇怪怪的问题;
- 全源码,搜索代码或者 Debug 都方便。
缺点
- 无法并发构建,当一次性修改多个组件时只能由该台构建机器单独完成改动组件的构建;
- 无法在多台机器间复用编译产物,导致在不同的机器上需要重复编译;
- 如果改动的头文件层级比较深,那么上层组件都需要重新生成,耗时增加;
- 无法提早发现循环依赖或者错误依赖。
总结
上面两种生成方案各有利弊,并没有说哪种方案就是完美的,需要根据项目实际的情况和人员配置来选择合适的方案。我们团队的方案分成两部分:
- 对于三方库和二方库,通过壳工程来编译,生成二进制产物上传到服务器缓存和共享,原因是我们的构建系统对工程配置和代码规范都有一定的要求,如果说三方库和二方库都通过构建系统来生成二进制产物,改动的工作量会比较大;
- 对于团队的组件库,则通过构建系统来生成二进制产物,同时使用自研的组件发版管理工具来简化组件构建和发版流程。
宏
上面提到组件和主工程编译环境不一致时会导致一些奇奇怪怪的问题,其中一个就是宏所带来的问题,下面展开说说。
跨组件宏
跨组件宏会带来两个问题:
下层组件改动宏,如果上层组件没有依赖新的下层组件进行重新编译,那么就会导致上层组件使用的还是旧的宏定义;
宏定义在组件工程和主工程中的编译配置不一致,导致两者的实现不一致,假设在底层组件 A 中有以下代码:
1 2 3 4 5 6 7 8
// AComponent.h #if ENABLE #define ENABLE_VALUE 1 #else #define ENABLE_VALUE 0 #endif
在上层组件 B 的编译配置中设置
ENABLE == 1,那么组件 B 单独编译时ENABLE_VALUE为 1 。在主工程的编译配置中没有对ENABLE进行定义,那么编译主工程时ENABLE_VALUE为 0 。两者的ENABLE_VALUE不一致。如果我们需要各个工程的ENABLE_VALUE保持一致,那么就有可能带来一些问题。
__has_include
如果某个组件要提供给不同的宿主使用,需要给不同的宿主提供一些差异化的实现,有些同学会选择使用 __has_include 来实现,这样会导致以下几个问题:
- 组件的 Spec 文件会越写越大,需要提供不同的 Subspec ,接入不同的目录;
- 如果是使用组件工程单独编译,那么就需要添加不同 Target ,或者在编译时动态添加特定渠道的文件,编译选项的增加需要非常谨慎,每增加一个选项都会增加开发同学的心智负担;
- 迁移
__has_include所指向的文件时编译不会报错,导致缺失某个功能,需要等到运行时才有可能发现。
总结
上面是组件和宏一起工作时带来的一些问题,而宏本身也有一些别的问题:
- 多次调用代码量较大的宏,导致体积增大;
- 难以 debug 和查看代码逻辑;
- Swift 无法调用。
即使是组件通过源码来引入,如果使用了宏,也有可能需要在主工程的 Podfile 中来对编译配置进行调整,导致 Podfile 的代码量增大。
我的看法是除非某个功能一定要用宏才能实现时才使用宏,否则都是通过函数和运行时来决定。知乎上有个相关讨论:什么时候应该使用宏定义?
Subspec
为了方便对同一个 Spec 仓库内的代码进行模块划分, CocoaPods 提供了 Subspec 的能力。不同的 Subspec 提供不同的业务能力,接入方可以根据自己需要选择不同的 Subspec 。具体解析可以看这篇文章:5. PodSpec 文件分析
但是当业务组件使用 Subspec 时会带来不少问题。
- Subspec 具有传染性,当某个底层组件增加一个 Subspec ,针对某个宿主进行差异化时,上层组件如果有依赖对应的实现,也需要添加对应的 Subspec ,增加
podspec文件的维护难度; - 当直接使用源码 Subspec 时,都是通过主工程的构建来生成二进制产物,使用起来比较方便,不需要新建仓库和单独管理,直接新建一个目录,然后把文件迁移下位置就好了,但是当支持组件单独构建,自行生成二进制产物时,就要针对不同的 Subspec 进行管理了,主要有以下两套方案:
- 多 Target ,每个 Subspec 有自己 Target 。编译时可以采取指定的 Target 才生成产物,或者所有的 Target 都进行编译,这两种选择都有缺点。指定 Target 会增加构建选项,组件一多,操作起来就比较繁琐。所有 Target 都进行编译会增加编译耗时,本地下载产物时还要下载无用的 Subspec 产物。
- 单 Target ,编译时指定目录,动态添加文件,其缺点就是多 Target 时指定编译 Target 一样,会增加构建选项。
所以建议对粒度比较大,基础能力或者业务较多的组件进行隔离,分成粒度更小的,基础能力和业务更加纯粹的组件库,减少组件二进制的难度和编译选项,也更容易进行代码权限管理,而不是在一个大的仓库里,大家都往里面提交代码。
工程质量
Objective-C 作为一门基于 C 的语言,采取了“信任程序员”的做法,给程序员极大的发挥空间,当使用 Objective-C 编写不规范时,很多情况下只会得到警告,不会报错。警告这个东西就比较奇妙了,会有破窗效应,要么零个,要么无数个,要求项目里没有警告也不现实,又不是不能用,因此警告的作用基本上约等零。而且在频繁的业务迭代需求中,要求大家都进行 Code Review 也不现实,所以我们通过 git hooks 和借助编译器来添加工程规范,尽量提高工程质量。
git hooks
这是团队其他同学写的如何通过 git hooks 来进行工程规范管理的文章:
通过 git hooks 我们可以添加一些自定义的规则:
- 图片资源大小限制;
- API 限制;
- git commit 信息规范;
- 等等。
借助编译器
前面提到 Objective-C 在编写不规范时大多数情况下只会得到警告,不会报错。而通过编译器的设定,我们可以将一些警告改为报错,从而提高代码质量,避免一些运行时的错误,毕竟编译时的错误肯定要比运行的错误要好。
通过在 Xcode 工程 Build Settings 的 Other Warning Flags 中将对应的警告标记为错误,举几个例子:
-Werror=unused-variable,如果有未使用的变量,在编译时报错;-Werror=protocol,@protocol相关的警告改为报错,比如说@required的方法没有实现;-Werror=implicit-retain-self,隐式的持有self,有可能会造成循环引用。
可以查看下面的文档,根据自己的需要添加对应的报错规则:
也可以通过在 Podfile 的 post_install 中设置 config.build_settings['WARNING_CFLAGS'] 来给 Pod 库添加规则:
1
config.build_settings['WARNING_CFLAGS'] = ['-Werror=protocol', '-Werror=arc-unsafe-retained-assign', '-Werror=implicit-retain-self']
组件通讯
组件间为了避免相互之间有依赖,都会通过通讯方案来进行解耦,一般来说有以下几种方案:
- 基于路由 URL ;
- 基于 Target-Action ;
- 基于 Protocol-Class 。
基于 URL 的好处是其本身是一种跨端的协议, iOS ,Android 和 Web 可以统一使用,但是无法直接传输原生数据,需要进行一定的改造。且需要进行硬编码,增加维护成本。
基于 Target-Action 的方案比较出名的就是:CTMediator
相关文章:iOS应用架构谈 组件化方案
Target-Action 方案的缺点就是需要编写大量的胶水代码,而且还是需要进行字符串硬编码。
基于上面提到的问题,以及我们项目本身就有使用基于 Protocol-Class 的方案。为了减少团队成员的理解成本,目前我们大部分的情况还是使用 Protocol-Class 的方案,提供了两种匹配方式:
- 手动注册,把相关的 Protocol-Class 转为字符串的形式打进 Mach-O 的 Data Section 字段,运行时读取;
- 自动注册,自定义的字符串匹配规则。
如何把字符串打进 Mach-O 的 Data Section 字段可以参考这里:一种延迟 premain code 的方法 。
运行时优先看 Mach-O 里面手动注册的部分是否有对应 Class 数据,如果有,就调用该 Class 的方法来处理。如果没有,就走自定义的字符串匹配规则。比如说有协议: IYYAClass ,我们团队中使用 I 开头来表示协议。然后我们会通过 YYAClass , AClass 字符串来查找是否有对应的 Class ,如果有找到对应的类且有实现协议,就调用该 Class 。
通过字符串的自动匹配,大部分情况可以省去手动注册的步骤,然后如果匹配规则无法满足需求,或者上层业务方需要覆盖底层 Class 的实现,也可以通过手动注册的方式。这套方案目前使用起来还是比较舒服的,对开发同学的影响比较小,也没有字符串硬编码,当然了,不同团队的业务和架构情况都不同,根据自己团队的情况选择合适的通讯方案才是最好的。
去工程化
上面提到组件目前是通过单独编译来生成二进制产物,那么就需要单独管理组件的 Xcode 工程。这样带来的一个问题就是新增/删除/迁移文件时,操作都比较繁琐,需要在组件的 Xcode 工程中同步进行操作。所以我们采取动态生成 Xcode 工程的方式。比较流行的开源方案有以下几种:
可以根据自己的实际需求来选择对应的方案,采取动态生成 Xcode 工程的好处如下:
- 可以从 git 中移除
.xcodeproj,不再需要处理相关冲突; - 目录的文件会自动保持同步,不需要手动管理;
- 进行工程配置时可读性更高,同时对 git 的处理也更加友好;
- 拷贝文件时不再需要在 Xcode 中进行编辑;
- 等等。
差异化
只要有不同的宿主,就会有差异化的需求。团队的差异化实现迭代过两个版本。在 1.0 版本,我们有以下几种方案来实现差异化:
- 配置表,在 plist 文件填写差异化数值;
- 头文件放在公共目录,实现层在各自的差异化目录下;
- 通过 Protocol-Class 的方式,
Class实现可以放在同一组件内,也可以放在上层组件。
不管是方案 1 还是方案 2 ,我们都需要使用 Subspec ,其缺点上面有提到,且因为差异化的方式有多种,没有统一起来,增加开发同学的理解成本。由于我们已经采用了 Protocol-Class 的方式来进行组件通讯,在差异化的解决方案上我们也决定改为统一采用 Protocol-Class 。
先说下为什么要使用差异化,举个例子,比如说有个自定义控件 DTButton ,我们期望在 A 宿主上其圆角 cornerRadius = 5 ,然后在 B 宿主上其圆角 cornerRadius = 8 ,但是这个 DTButton 的使用是分散在各个组件的内部的,我们无法在所有实例化的地方都手动进行设置,这个时候需要一个方案可以统一进行设置。
基于 Protocol-Class 的方式我们可以实现以上需求,其和组件通讯的不同点如下:
- 差异化
Protocol定义是在组件的接口仓库或者组件自己的仓库,Class实现是在上层组件,一般会是宿主自己单独持有的组件,举个例子,我们会在IDTButtonDiff上定义需要进行差异化的相关方法,可以返回任何原生类型,包括UIImage/UIColor/CGFloat等,然后DTButton内部会通过和组件通讯相同的方式来访问IDTButtonDiff,再往上一层是DTButtonDiff,负责实现IDTButtonDiff协议,返回宿主的差异化数据,再往上就是 App 了: - 组件通讯
Protocol定义可以在公共的接口仓库,也可以在组件的接口仓库,Class实现是在组件内部。
整体的层级如下:
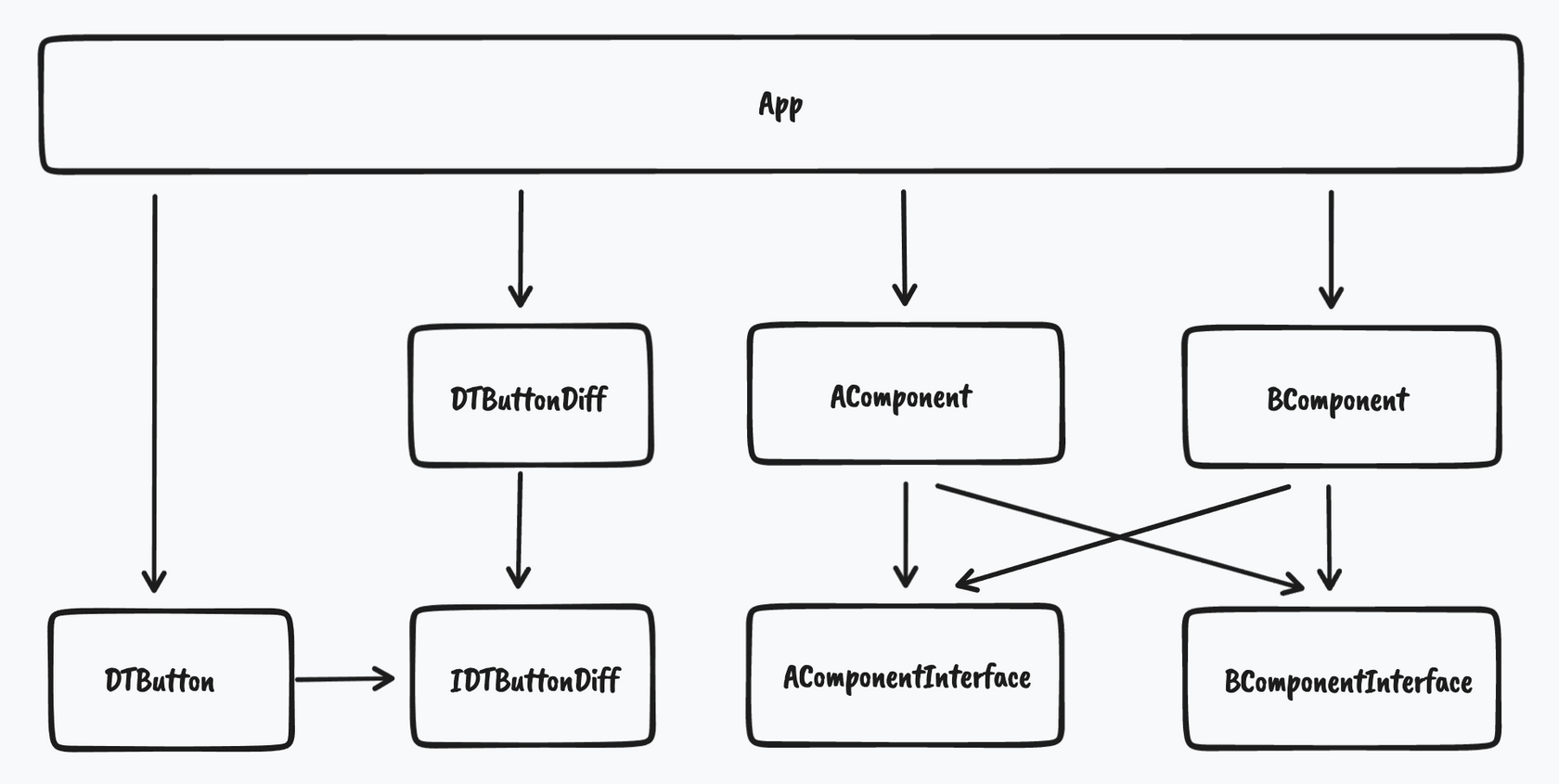
通过这种方式我们还可以完全替换某个控件,交由宿主来负责实现,比如说 DTButton 对应的协议为 IDTButton ,其实现了 DTButton 对外提供的方法,然后统一通过和组件通讯相同的方式来访问 IDTButton ,上面有提到我们有字符串匹配的规则,所以这个时候会获取 DTButton 的实例。如果说宿主想完全接管 DTButton 的实现,可以通过上面提到的手动注册方式,为 IDTButton 注册一个新的实现 AAButton ,从而使得通过 IDTButton 协议获取到的实例都是 AAButton ,更加灵活和通用,也可以干掉 Subspec 。
这套差异化方案目前用下来还不错,而且通过 @protocol 的 @required 和 @optional 标注可以更加清晰地描述哪些配置是必须的,哪些是提供默认实现的,减少理解成本。
生命周期统一管理
比起一般的组件化,我们团队的组件化需要处理的宿主更复杂一点。业务组件不仅需要提供给 YY iOS App 使用,也需要提供给百度系的 App ,作为 SDK 来使用。两者的生命周期不太相同。在 YY iOS App 上,组件的生命周期和 App 的生命周期可以是一致的,启动时就会进行初始化,但是在百度系的 App 上,只有当用户进入了 YY 的直播间才会初始化 SDK 。
在一开始,我们选择手动初始化的方式,根据组件的要求,在对外提供的 SDK 初始化方法上添加需要调用的组件初始化方法。如果组件新增了初始化方法,就要手动在 YY iOS App 和 SDK 上同步。
这样会带来以下几个问题:
- 中心式的写法,导致上层调用部分的代码量会非常大,增加维护难度;
- 新增初始化方法时需要手动在各个宿主上同步添加,容易遗留;
- 无法自动测量各个方法的耗时,需要手动统计。
为了解决上面的问题,可以采取去中心化的方案,各个组件自己管理自己生命周期的相关方法。整体的实现原理和基于 Protocol-Class 的组件通讯方法类似,分为编译时和运行时两部分,编译时写入相关的注册类,运行时再读取,执行对应的方法。这里直接采用写入 Class 信息的做法,然后实现协议中的方法。使用协议的原因有以下几个:
- 当需要在生命周期某个阶段中调用组件的方法时,可以查看协议的方法说明,选择适合的方法;
- 与
UIApplicationDelegate的方法类似,方便处理传递过来的参数,比如说(UIApplication *)application和(NSDictionary *)launchOptions; - 某个组件内生命周期的方法可以集中到一个
Class内,方便管理和统计。
为了解决上面的问题,可以采取去中心化的方案,各个组件自己管理自己生命周期的相关方法。整体的实现原理和基于 Protocol-Class 的组件通讯方法类似,分为编译时和运行时两部分,编译时写入相关的注册类,运行时再读取,执行对应的方法。这里直接采用写入 Class 信息的做法,然后实现协议中的方法。使用协议的原因有以下几个:
- 当需要在生命周期某个阶段中调用组件的方法时,可以查看协议的方法说明,选择适合的方法;
- 与
UIApplicationDelegate的方法类似,方便处理传递过来的参数,比如说(UIApplication *)application和(NSDictionary *)launchOptions; - 某个组件内生命周期的方法可以集中到一个
Class内,方便管理和统计。
对应的实现在这里:DTComponentLifeCycle
- 生命周期相关方法在
IDTComponentLifeCycle.h,用法可以看下里面的说明和 Demo ; IDTComponentLifeMetric用于统计各个组件的调用情况,调用registerMetricObservers进行注册;DTComponentLifeCycleManager负责调用组件生命周期的方法,由于在 YY iOS App 和 SDK 上的生命周期处理不同,这里没有用 hook ,我也不太喜欢用 hook ,如果有需要可以改用 hook 来实现,可以减少点代码量;- 由于在 SDK 上是用户进入直播间后才会初始化,所以在 SDK 的初始化里手动一次调用生命周期关于初始化的方法即可。
最后
上面说了这么多,整个工程的基石还是我们日常开发中所编写代码的质量,重复代码是否有封装起来,而不是简单复制粘贴,是否有留意编译器报的一些警告,代码实现有没有考虑一些边界条件,比如调用 block 前是否有判空等等。如果日常开发的代码质量比较低,那么无论工程建设做得多好也是没办法弥补的。作为一名开发者,应该对代码抱有敬畏之心,持续提高代码质量,那么不管是后面做工程化建设还是其它一些改进都会非常容易着手。
Comments powered by Disqus.